Java 프로그래밍 초급(4) - 컬렉션 프레임워크 : 개념, 제네릭
안녕하세요~ 항상 나아가는 개발자 pink_salt 핑솔입니다!

코드프레소 Java 웹 개발 체험단 활동을 하고 있습니다.
Java의 정말 중요한 개념인 컬렉션 프레임워크 : List 에 대해서 알아봅시다~ 고고!
이번엔 'Java 프로그래밍 초급' 강의를 듣고 공부한 내용을 정리하여 네 번째 포스팅을 진행하겠습니다.
컬렉션 프레임워크(collection framework)란?
- 여러 건의 데이터를 다루기 위해서 Array와 같은 데이터를 다루기 위한 자료구조의 구현체가 필요하다.
- 다양한 특성을 가진 데이터를 다루기 위해서는 그에 적합한 자료구조가 필요하다.
- 다양한 자료구조의 구현을 위한 클래스와 인터페이스의 집합이다.
필요성
다양한 자료구조의 구현체를 클래스 라이브러리 형태로 제공합니다.
1. 만약 매 분마다 수집된 하루치 주식 가격 데이터를 다룬다고 생각하면
today_stock_prices = [34500, 34200, 34000, 34100, ... , 35600]
- 저장되는 데이터에 순서가 존재합니다.
- 중복되는 데이터가 저장될 수 있습니다.
=> java.util.ArrayList<E>
2. 전 세계 모든 국가들의 이름을 GDP 순으로 저장한다면
names_of_country = [Korea, USA, China, ..., Togo]
- 저장되는 데이터에 순서가 존재합니다.
- 중복되는 데이터가 저장될 수 없습니다.
=> java.util.HashSet<E>
3. 한 사람의 정보를 저장한다면
personal_info = {'name' : 'Jinsoo Kim', 'gender': 'Male', 'height': 180, 'nationality': 'Korea'}
- 하나의 데이터를 설명하기 위한 여러 속성 정보가 필요합니다.
- 속성 간에는 순서가 필요 없습니다.
- 동일한 속성으로 여러 개의 값이 존재하지 않습니다.
=> java.util.HashMap<K,V>
이렇게 자료구조에 저장되어 있는 데이터를 다루기 위해서는 알고리즘 구현체가 필요합니다.
- 데이터의 조회
- 데이터의 삭제
- 데이터의 추가
- 등등
이것은 위에서 빨간색으로 표시한 글씨로 보이는 제공되는 클래스에서 데이터를 가공하기 위한 메서드를 제공합니다.
java.util.ArrayList<E>
▶ .add()
▶ .get()
▶ size()
▶ remove()
java.util.HashSet<E>
▶ .add()
▶ .addAll()
▶ size()
▶ remove()
java.util.HashMap<K,V>
▶ .put()
▶ .get()
▶ size()
▶ remove()
컬렉션 프레임 워크 클래스와 Array
Array와 컬렉션 프레임워크 클래스 차이
- Array와는 다르게 데이터 개수의 동적인 변경이 가능합니다.

- Array의 element는 Primitive Type의 원소를 가질 수 있었지만 ArrayList는 Object 형태로 element를 가질 수 있습니다. -> 객체만을 원소로 가집니다.

컬렉션 프레임워크의 주요 인터페이스
- 컬렉션 프레임워크에는 아래의 주요 인터페이스가 정의됩니다.

- List와 Set 인터페이스는 모두 Collection 인터페이스를 상속받아 정의합니다.
- Map 인터페이스는 구조상 차이로 Collection 인터페이스를 상속받지 않습니다.(독자적 인터페이스 구현)
컬렉션 프레임워크 인터페이스들의 상속 관계
- java.util.Collection<E> 인터페이스 그룹

- java.util.map<K,V> 인터페이스 그룹

주요 인터페이스들의 특징
- java.util.List<E> 인터페이스

▷ 순서가 있는 데이터의 집합
▷ 데이터들의 중복을 허용합니다.
ex) 위에서 말한 주식 데이터
- java.util.Set<E> 인터페이스

▷ 순서가 없는 데이터의 집합
▷ 데이터들의 중복을 허용하지 않습니다.
ex) 위에서 언급한 나라 이름 별 GDP 순
- java.util.Map<K,V> 인터페이스
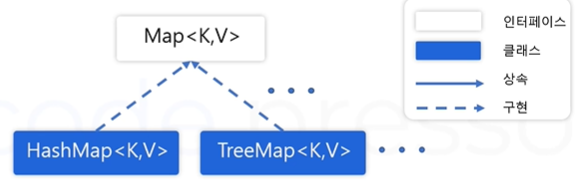
▷ Key, Value로 이루어진 pair를 갖는 데이터의 집합
▷ 데이터들 간의 순서가 없습니다.
▷ Key는 중복을 허용하지 않습니다.
▷ Value는 중복을 허용합니다.
ex) 위에서 언급한 사람 정보
제네릭과 컬렉션 프레임워크
오브젝트 형태로 데이터를 받는데 그 과정에서 발생하는 문제를 해결하기 위해 제네릭을 활용해 어떤 장점을 갖게 되는지 알아보겠습니다.
제네릭(generic)이란?
- 제네릭(generic)이란 데이터의 타입을 일반화한다(generalize)는 것을 의미합니다.
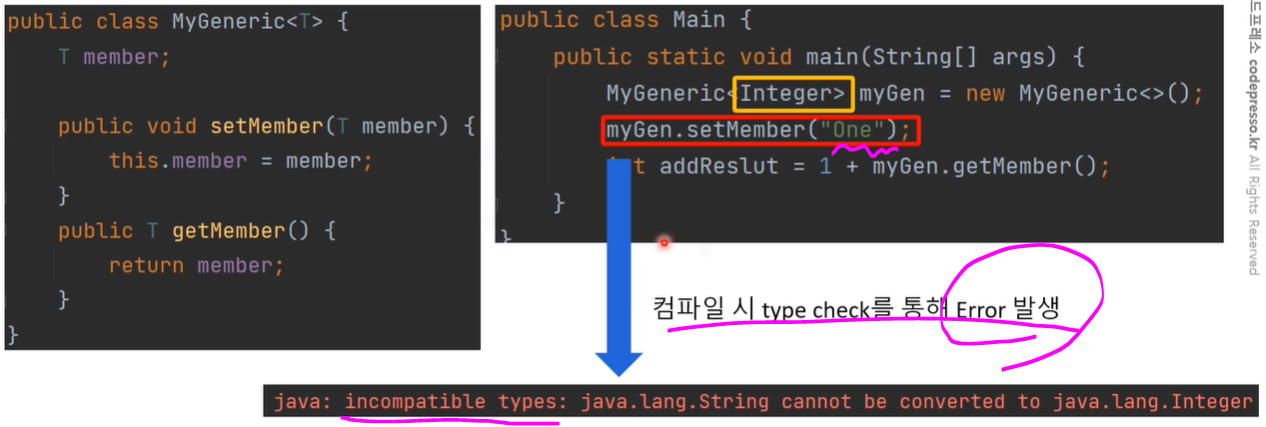
- 클래스나 메소드에서 사용할 데이터의 타입을 컴파일 시 type check 하여 런타임 시의 안정성이 보장됩니다.
제네릭의 사용
- 제네릭을 사용한 클래스 정의 문법
class ClassName<T> {}
→ <T> :
- 클래스 내부에서 사용될 임의의 데이터 타입을 'T'라는 type variable로 지정합니다.('T'는 Type의 약어로 관행적으로 사용되는 이름입니다.)
- type variable 'T'를 이용해 클래스 내부 변수 생성 및 메서드 인자, 반환 값의 타입 지정이 가능합니다.
- 'T'라는 type variable은 임의 값으로 지정 가능합니다.
- 제네릭을 사용한 클래스 정의

member라는 멤버 변수를 T라는 데이터 타입으로 선언한다.
밑의 두 메소드는 void, T 리턴 타입을 지정하고 void 함수는 인자로 T타입의 member 변수로 지정하였다.
-> 클래스 내에서 제네릭 한 데이터 타입을 쓰겠다고 하면 클래스 이름 옆에 <> 안에 type variable을 넣어주면 멤버 변수 타입, 리턴 타입, 인자 타입 등을 지정할 수 있습니다.
- 제네릭을 사용한 클래스 객체 생성 문법
ClassName<Type-Class> object-name = new ClassName<>();- ClassName : 생성하고자 하는 Class 지정
- <Type-Class> : 클래스 정의 시 지정한 type variable에 사용할 실제 데이터 유형 Class입니다.
- Primitive Type 데이터의 경우 Wrapper Class를 사용합니다.
- ex) int => Integer, double => Double, float => Float, etc...

T로 설정한 제네릭이 Integer로 치환돼서 메서드를 우리가 사용하고 싶은 데이터 타입으로 사용할 수 있습니다.
제네릭의 장점
- 매개 변수의 범용성(generality) 확보할 수 있습니다.
- 클래스 내 임의의 변수를 매번 다른 데이터 타입으로 지정하여 객체 생성이 가능합니다.

- 컴파일 시 type check로 인한 런타임 안정성을 확보할 수 있습니다.
- 타입 변환 및 타입 검사에 들어가는 노력을 줄일 수 있습니다.
- Object Class 인자로 이용한 Class 정의할 때보다 더 큰 장점을 보입니다.
- object는 최상위 Class로 제네릭과 같은 범용성 확보 가능합니다.
- 컴파일 시 type check 미수행으로 안정성이 저하됩니다.
- Class에 적합하지 않은 데이터 타입을 사용해도 error가 발생하지 않습니다.
- 컴파일 시 발견되지 않은 error가 런타임 시 발생할 수 있습니다.
- 불필요한 명시적 형 변환으로 인한 성능이 저하됩니다.
ex) Object로 정의했을 때

위의 코드와 같이 범용성 확보가 가능하지만

위의 코드와 같이 object 데이터 타입으로 반환되어서 만약 int 타입의 데이터와 연산을 하였을 때 에러가 발생할 수 있습니다.
그래서 위의 에러를 없애기 위해서는 명시적으로 형 변환을 해줘야 합니다. 이때 성능 저하가 발생하게 됩니다.

하지만 제네릭을 이용해 범용성을 확보하면 명시적 형 변환이 필요 없습니다.

컬렉션 프레임워크의 클래스와 인터페이스들은 제네릭을 이용해 데이터 타입의 범용성을 확보할 수 있습니다.<E> ->element
<K, V> -> key, value

다음 게시물에서는 List 자료구조 컬렉션 클래스에 대해 자세히 공부하고 정리해서 다시 찾아뵙겠습니다!
열심히 나아가는 개발자 핑솔이었습니다.
go go!
코드프레소 URL: https://www.codepresso.kr/
프리미엄 IT 교육 서비스 - 코드프레소
www.codepresso.kr